Instalación de Splunk en Linux: base real para un entorno SIEM

Introducción
En este artículo voy a explicar el proceso de instalación de Splunk Enterprise en un entorno Linux orientado a laboratorio.
La idea no es solo instalar la herramienta, sino sentar una base sólida sobre la que poder trabajar posteriormente aspectos clave en un SIEM como la ingestión de datos, el parsing, la generación de alertas o la construcción de una arquitectura distribuida.
Este tipo de instalación “all-in-one” es habitual en entornos de pruebas, ya que permite tener en una única máquina los roles de forwarder, indexer y search head, simplificando mucho el despliegue inicial.
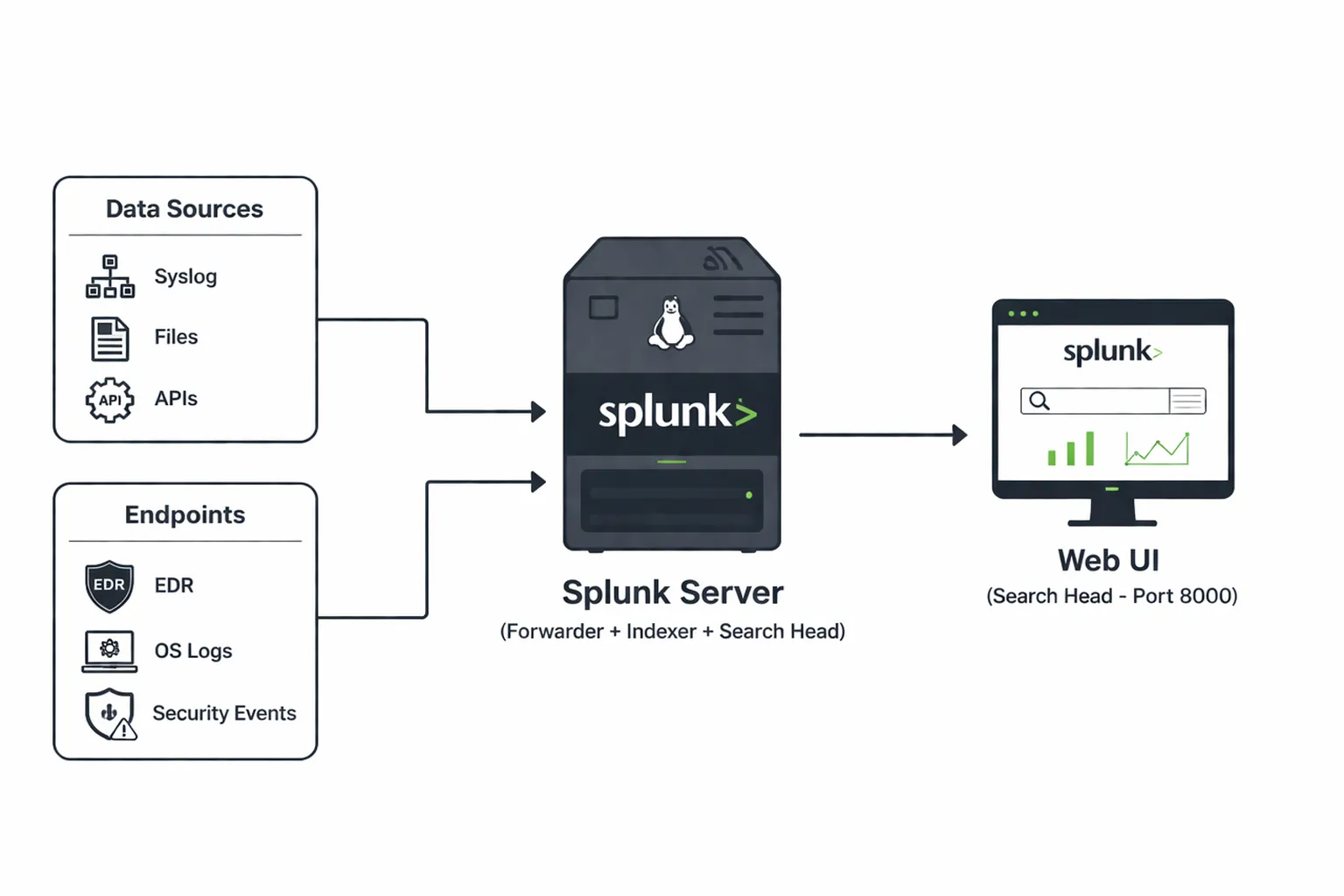
A lo largo del artículo iré detallando los pasos más relevantes, junto con algunas recomendaciones prácticas que suelo aplicar desde la primera instalación para evitar problemas más adelante.
Requisitos previos
Antes de comenzar la instalación, es importante contar con un entorno de laboratorio adecuado y entender qué impacto tienen estos requisitos en el funcionamiento de Splunk.
Para este laboratorio utilizaremos una configuración sencilla, pero suficiente para trabajar con ingestión de datos y pruebas básicas de análisis.
Sistema operativo compatible:
- Ubuntu Server 22.04 (recomendado)
- Rocky Linux / AlmaLinux (alternativas a CentOS)
Recursos mínimos recomendados:
- CPU: 2 cores
- RAM: 8 GB (4 GB puede funcionar, pero con limitaciones)
- Disco: 20-30 GB (dependiendo del volumen de logs)
Conocimientos previos:
- Uso básico de Linux
- Manejo de terminal (bash)
- Conceptos básicos de logs y sistemas
Descargas necesarias:
Desarrollo paso a paso
1. Crear usuario dedicado para Splunk
Una buena práctica en cualquier despliegue es ejecutar Splunk con un usuario dedicado y sin privilegios de administrador.
Esto permite:
- Aislar el servicio
- Controlar mejor los permisos sobre los logs
- Reducir riesgos en caso de compromiso
1
2
3
sudo useradd -m -s /bin/bash splunk
sudo passwd splunk
sudo usermod -aG adm splunk
Nota: No es recomendable añadir el usuario splunk al grupo sudo, ya que el servicio no debería ejecutarse con privilegios elevados.
2. Descarga e instalación de Splunk
El paquete de Splunk Enterprise se descarga desde la web oficial (requiere registro).
Una vez descargado, lo instalamos en /opt, que es el directorio habitual para este tipo de aplicaciones de terceros.
1
2
3
wget -O splunk.tgz "<URL_DESCARGA_SPLUNK>"
sudo tar -xzf splunk.tgz -C /opt
sudo chown -R splunk:splunk /opt/splunk
En entornos reales, es habitual automatizar este proceso o utilizar repositorios internos.
3. Iniciar Splunk por primera vez
En el primer arranque, es necesario aceptar la licencia de Splunk y configurar el usuario administrador que vamos a utilizar en la WebUI.
1
sudo -u splunk /opt/splunk/bin/splunk start --accept-license
4. Configurar arranque automático
Para que Splunk arranque automáticamente tras reinicios del sistema, habilitamos el servicio mediante systemd.
1
sudo /opt/splunk/bin/splunk enable boot-start -user splunk --accept-license
Esto crea el servicio splunkd y permite gestionarlo posteriormente con systemctl.
Verificación y validación
Una vez completada la instalación, es importante validar que Splunk se ha desplegado correctamente y que todos los componentes están funcionando como se espera.
1. Comprobación del estado del servicio:
1
sudo /opt/splunk/bin/splunk status

Esto debería indicar que el servicio splunkd está en ejecución.
2. Verificación del proceso:
1
ps aux | grep splunkd
Permite comprobar que el proceso está activo a nivel de sistema.
3. Verificación del puerto:
1
ss -tulnp | grep 8000
Deberías ver el puerto 8000 en escucha, asociado al proceso de Splunk.
4. Revisión de logs de arranque:
1
sudo tail -f /opt/splunk/var/log/splunk/splunkd.log
En este archivo log (splunkd.log), puedes detectar posibles errores relacionados con permisos, configuración o recursos, si trabajas con Splunk, este archivo será parte de tu día a día.
5. Acceso a la interfaz web:
Accede desde el navegador a:
http://<ip_del_servidor>:8000
Si todo ha ido bien, deberías ver la pantalla de login de Splunk.
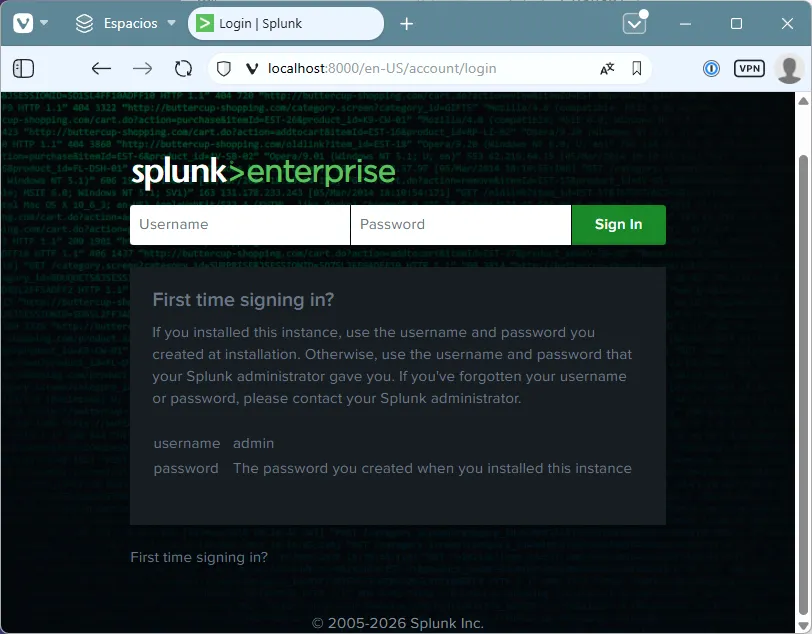
Estas comprobaciones son especialmente útiles en entornos reales, donde Splunk puede arrancar pero no estar funcionando correctamente debido a problemas de configuración o recursos.
Diferencia entre init.d y systemd
Dependiendo del sistema operativo, Splunk puede gestionarse como servicio mediante init.d o systemd. Aunque ambos cumplen la misma función, existen diferencias importantes.
En sistemas modernos (Ubuntu 20.04+, Rocky, AlmaLinux, etc.), el estándar es systemd, mientras que init.d se encuentra en sistemas más antiguos.
systemd (recomendado y actual):
Es el sistema de gestión de servicios estándar en la mayoría de distribuciones modernas.
1
2
3
4
sudo systemctl status splunk
sudo systemctl start splunk
sudo systemctl stop splunk
sudo systemctl enable splunk
También puedes verificar los servicios activos:
1
sudo systemctl list-units --type=service | grep splunk
init.d (legacy):
Presente en sistemas antiguos o en entornos donde systemd no está disponible.
1
2
sudo service splunk status
ls /etc/init.d/ | grep splunk
En la práctica, si has utilizado el comando enable boot-start, Splunk habrá configurado automáticamente el servicio según el sistema de init disponible.
En entornos actuales, te encontrarás prácticamente siempre con systemd, por lo que recomiendo familiarizarse con sus comandos para la gestión del servicio.
Buenas prácticas / Tips
Aquí algunas recomendaciones que suelo aplicar desde el inicio en cualquier despliegue de Splunk, especialmente en entornos orientados a SIEM:
Ejecutar Splunk con un usuario dedicado (
splunk)
Evita ejecutar el servicio como root. Esto mejora la seguridad y facilita la gestión de permisos sobre fuentes de datos.Definir correctamente los índices desde el inicio
Crear índices personalizados desde el principio ayuda a organizar mejor los datos y evita problemas de rendimiento o desorden en fases posteriores.Configurar la zona horaria correctamente
Es clave para la correlación de eventos y análisis temporal.
Settings → Server settings → General settings → Time ZoneSeparar datos por sourcetype e index de forma coherente
Una buena clasificación desde el inicio facilita búsquedas, detecciones y mantenimiento del entorno.Monitorizar el consumo de recursos
Splunk puede consumir bastante CPU y memoria. Es importante vigilar el uso de recursos, especialmente en entornos all-in-one.Revisar logs internos de Splunk periódicamente
El archivosplunkd.loges clave para detectar problemas de parsing, ingestión o errores de configuración.Realizar backups del directorio
/opt/splunk/etc
Aquí se almacena toda la configuración (inputs, props, transforms, etc.). Perder esto implica perder gran parte del trabajo realizado.
Lecciones aprendidas
Después de trabajar con Splunk en distintos entornos, hay algo que se repite bastante: una mala base suele traducirse en problemas futuros.
Detalles como ejecutar el servicio con el usuario correcto, definir bien la estructura desde el inicio o entender cómo funciona la ingestión de datos marcan la diferencia cuando el entorno empieza a crecer.
En laboratorio puede parecer que todo funciona, pero en escenarios reales cualquier mala decisión inicial acaba afectando a la estabilidad, al rendimiento o incluso a la capacidad de detección.
Recursos adicionales
Cierre
Con esta instalación ya tienes un entorno funcional sobre el que empezar a trabajar con Splunk de forma realista.
En los siguientes artículos iremos avanzando sobre esta base, entrando en aspectos clave dentro de un SIEM como la ingestión de datos, configuración de inputs, parsing, normalización y construcción de detecciones.
La idea no es solo aprender a usar Splunk, sino entender cómo se comporta en escenarios reales y cómo construir sobre él una plataforma útil de seguridad.
Gracias por llegar hasta aquí. Espero que te haya resultado útil. Seguimos.